
导读:推荐技术在迭代思路上已经形成一套成熟的范式,通过对经典算法的解构与重组,通常能够产出效果不俗的场景模型。但随着迭代的持续深入,一些共性路径上的迭代已经很难带来更多收益,此时便需要更多去思考场景的特性。今天将以全民K歌的直播推荐系统为例,为大家分享我们在互动场景下的推荐思考。
所谓互动场景,即所推荐的内容具有动态变化性,譬如主播的推荐、歌房的推荐等,这一特质将影响用户的行为动机,也将影响推荐系统的交互逻辑。今天的介绍会围绕如下四点展开:
- 推荐系统的共性与特性
- 如何更好地做用户冷启
- 如何更好地对先验建模
- 如何更好地对场景建模
01
推荐系统的共性与特性
首先我们来看看推荐迭代的共性路径。
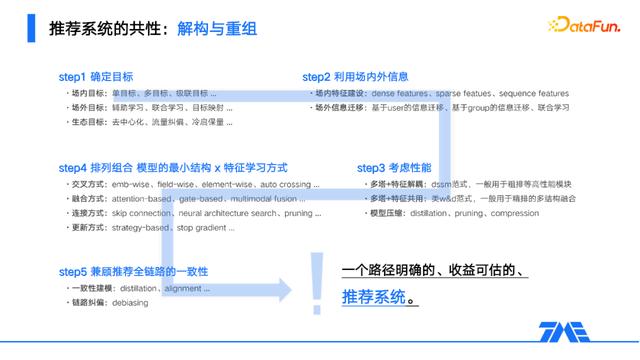

- 首先先确定目标
此处的目标是一个广义上的概念,既包括场景内的行为多目标,如互动目标、点击目标等;也包括场景间的联合目标,如优化多场景的总时长、总营收等;此外还包括生态目标,譬如内容的时效与多样性、生产者的激励与冷启、流量的纠偏与定向供给等。推荐系统作为一个终端系统,要求我们必须承担更加全局的思考,要有消费者视角、生产者视角,还要有平台视角,才有可能构建出具备长期价值的系统。
- 然后将场内外信息进行一个完备的输入
通常场内信息以特征构建的方式进行输入,而场外信息则通过一些信息传递的手段,譬如基于embedding、基于模型蒸馏、基于辅助学习的方式进行信息迁移。但跨域的信息或多或少是存在信息偏移的,引入时最好有一个消弭偏差的过程,既可以是局部的联合学习来做信息融合,也可以是以类似fine-tuning的方式来做对齐,此外multimodal fusion也提供了一些其他思路。
- 性能上的考量
推荐系统通常是一个级联架构,不同层级都在做着性能与精度的平衡。对于粗排等有性能压力的模块,可以用多塔的结构来实现计算解耦,分散受力,也可以用模型压缩、特征筛选等方式来降低模型规模和复杂度。而对于下游侧重精度的精排重排模块,通常会给予较高的性能容忍度。
- 模型细节的具体构建
推荐领域的优质算法众多,通过对大模型的解构,可持续积累有效的模型单元,譬如gate、attention、fm、dcn等,再组合特征的不同使用方式,在交叉、融合、连接、更新机制上做路径化探索,至此便可填充出一个适配场景的较优模型。
- 考虑一些链路上的问题
通常会做全链路的一致性建模和纠偏,来防范上下游各模块的优化目标不对齐而导致的错位折损,以及缓解系统内不断累积的数据偏差。

前述路径可以快速取获推荐系统的标准收益,但随着迭代的深入,则需要展开更多对场景特质的思考。譬如对于互动场景而言,所推荐的是实时的、动态的、真实的人。这会带来两个特点,其一是高门槛,去融入直播场景的玩法,天然就有更高的操作门槛和心理门槛,如此种种会使得低活跃用户更难向上转化。其二是强感知,主播是一个真实的人,而不是一段被创造出来的音乐或者视频,真实性会带来强烈的感知冲击,正如真实世界里的社交关系一样,第一感知尤为重要,在直播场景更如是。
—
02
如何更好地做用户冷启
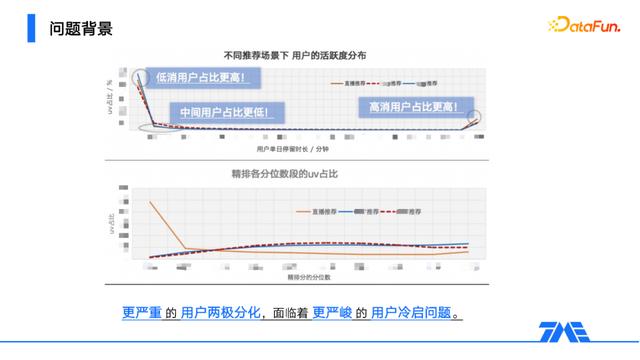
我们先来看看高门槛会对系统带来怎样的影响。
上图是从用户角度的观察,可以发现直播场景的两极分化尤为严重,绝大多数用户止步于低活跃阶段。我们可以认为模型在其预估值域内,打分越靠近下分位数点,则表示预估把握越低。
下图是从模型预估角度的观察,可以发现直播模型对大部分用户的预估分都落在了靠近下界的分数段,即并不能提供很好的推荐能力。表里综合来看,都说明直播场景中用户的分化严重,并且已经导致了推荐模型的局部失能,面临着更为严峻的用户冷启推荐问题。

用户冷启的思路有许多,有基于迁移学习的,有基于千人千模的,有基于独立建模的,但它们或是基于强假设,或是不完全可控,或是不能机制化地解决低活跃用户的行为被淹没的问题,或是有前置的预处理导致难以维护,似乎都不能很好地满足诉求。
我们考虑如上范式,通过无偏特征(性别、年龄等)先完成用户群聚类。无偏的性质使得不同活跃度的用户能够被划分到同一类簇中,由此便有了信息级差,为兴趣迁移提供了前置基础。
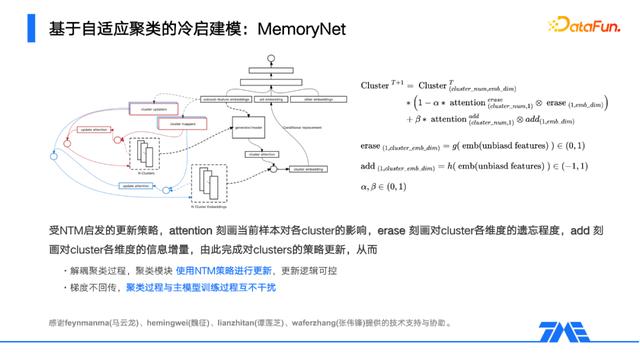
一个具体的实现如上。
逻辑上,选取无偏特征作为聚类模块的输入,计算当前用户到不同聚类(图中Clusters)的距离,基于此融合相应的聚类表征(图cluster Embeddings)成为用户的群表征,并作为新特征返回至模型输入层。群表征的信息是经由同聚类中的高活跃用户传递而来,由此可以弥补低活跃用户因行为稀疏而导致的表征不充分。在更新机制上,采用的是基于NTM的规则更新,其中attention表示对不同聚类的更新强度,而erase/add则分别决定了对具体信息的遗忘/新增,由此实现聚类模块与模型主体部分的分离更新,避免相互干扰。

对于一个聚类过程,很自然想到的就是通过提升类间分离度及类内紧致度来提升聚类质量。首先我们思考用户和聚类的关系,可以把用户理解为聚类中心的个性化偏移。看似是个性化的兴趣,但从大规模的群体视角来看,往往皆是共性,所谓的个性,不过是集体共性的向外试探。用shift emb去描述这段偏置,一些聚类方法证明,更小半径的shift emb,能带来更好的类内紧致性,从而使得聚类有更低的泛化误差。那么我们将shift emb的模长作为惩罚项加入损失,便完成了这一约束过程。
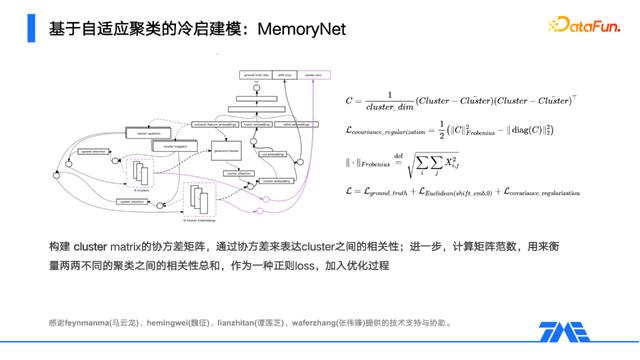
接着来优化类间分离度。我们通过聚类的协方差矩阵来描述,每个元素表示的是聚类间的两两相关性。类似地,我们将最小化两两不同聚类的相关性作为一项约束,由此完成了对聚类质量的整体提升。

此方案在全民K歌与QQ音乐的多个场景全量上线,我们进一步来思考下它的有效性来源。我们可以认为,一个经过学习的模型,其内部都会抽象学习出某种知识(key),这是提供精准推荐能力的基础,这些知识会传递到我们构造的聚类表征上,其次我们通过无偏特征去寻找用户和各个类簇的关系,实质上是一个query过程,获取到的就是知识在该特征上的投影(value),所以其实它实现的是特征冷启,用户冷启只是它的一个退化应用,进一步我们可以想到它的对称应用,就是做物品冷启。再进一步,既然是特征冷启,那么「无偏特征」这个假设是否需要?因为「无偏」其实是个相对的概念。
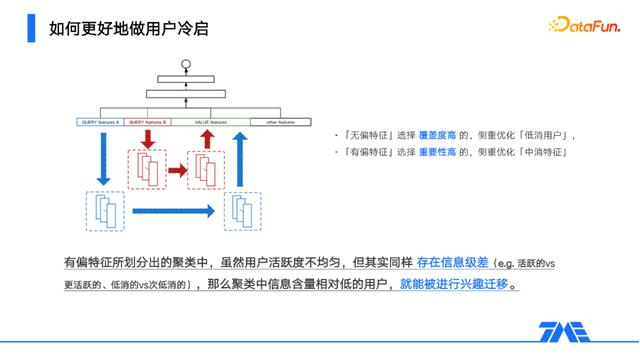
我们先来回顾一下前面提及的,之所以选择无偏特征进行划分,目的是为了使得划分出来的类簇中,存在不同活跃度的用户,由此产生的信息级差,使得高活跃用户的行为信息能传递到行为匮乏的低活跃用户上,从而实现用户冷启。但对于每一个有效特征,其实我们都可以认为它具备人群上的区分度,这是特征有效性的前提,区别是,不同偏置度的特征,划分出来的类簇里的用户活跃度极差会不同。基于相对无偏的特征,更多实现的是高活跃用户到低活跃用户的信息迁移,而基于相对有偏的特征,实现的是高活跃用户到中活跃用户的信息迁移,本质上都是在以特征为载体,做信息扩展,提升特征上的信息饱和度。
所以,除了无偏特征外,尽可同时尝试使用有偏特征。当然也要避免过度的堆叠,通常选取覆盖度高的无偏特征及特征重要性高的有偏特征足矣。
这里不禁有个疑问,用其他的模型学习,难道就学不到这种传递关系么,同一模型,本身不就在实现相似用户的相似推荐么?个人认为很难,路径的存在并不等同于目标的实现。样本是被高活跃用户主宰的,模型是被行为主宰的,低活用户是沉默的大多数,低活跃用户仅有的稀疏行为以及属性特征绝大多数时候会被淹没并成为模型盲点。譬如,对于低活跃用户而言,年龄性别等属性特征是极重要的,但对模型整体而言,一些行为序列具备更好的学习性,所以模型贪心地去学习这些特征,最后虽然获得了更好的指标效果,但其实始终是在优化少数人的体验。
而上述方案是如何处理这个问题的?做法是把一些特殊特征(譬如低活跃用户也拥有的年龄性别等属性特征)拎出来做信息扩展,并且将结果寄存在外部存储(cluster)里等待索引,那么每当对低活跃用户推荐时,就不会面临「自己所拥有的特征被模型忽视,模型所重视的特征自己又没有」的困境,而可以通过这些特征,从聚类信息中去取回模型的有效知识。
—
03
如何更好地对先验建模
接着我们来看看场景的真实性所带来的强感知,会对系统产生什么影响。

在互动场景里,我们通常会基于一些先验知识设计一些重排规则,譬如优先推荐同龄用户等,来获得一个更好的体感。
上图的横坐标是用户的单次停留时长,纵坐标是模型打分,两条曲线分别是重排和精排,我们希望曲线有着更高的斜率,因为那意味模型分数与用户停留时长有更高的相关性。具体来看这两条曲线,蓝色的重排曲线有着更大的震荡,这是符合预期的,因为重排是个弱个性化的约束,在个体的精准预测上是不鲁棒的,但同时可以发现重排曲线的上斜率是高于精排曲线的,这侧面反映了精排模型至少低估了重排环节的这些特征,所以没有达到一个更好的时长预测结果。
所以,当我们知道某些重要特征被模型低估时,我们就应当寻求一种机制化的、可优化的干预手段,而不是在重排阶段生硬地使用阈值或者排列组合搜索的策略来进行更新。
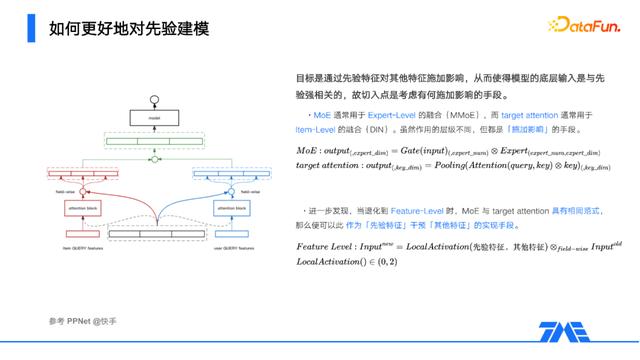
我们希望模型更重视某些特征,一个直觉的想法就是让这些特征去干预模型的输入层,形成主导。其实有许多结构都在起到这样「施加影响」的作用,譬如MoE是基于inputs来影响experts的融合,是一个expert-level的操作,而target attention则是基于item来做局部激活,是一个item-level的操作,但其实它们底层都是相同范式。类似于快手的PPNet,我们考虑做如此一个feature-level的操作,以先验特征为输入,输出一组值域在(0,2)的特征权重,作用在原始特征上,融合成最终的输入层。它的含义很明显,通过部分特征来筛选剩余特征,从而构成一种主从的依赖关系,它可以理解为特征级别的MMoE,每个特征都是一个expert,也可以理解为特征级别的target attention,那这便是个条件性激活特征的过程。
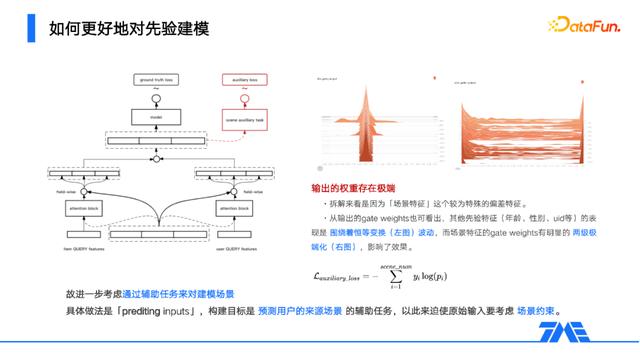
特征权重等于1时,等价于进行了恒等变换,如果特征值围绕均值1波动,则说明有取舍地强化/弱化了一些特征。但若特征权重的值两级化,说明模型过于极端地依赖/丢弃了部分特征,过犹不及。当选择一些场景类的偏差特征作为先验特征时容易发生这类现象,而通常场景类特征也确实是被拎出来单独处理的。既然不适合直接作为先验特征,我们考虑用其他的手段添加约束,譬如构建predicting inputs的辅助任务,即用输入去预测特征值,由此迫使输入层必须对此特征的取值更加敏感,也便是加入了约束,而这个约束的强度也可以通过权重超参数来调节。
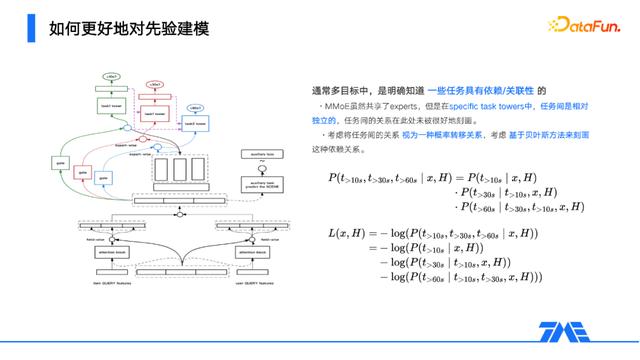
除了输入层的先验外,输出层同样存在先验,譬如我们通常会用多个不同时长阈值的子目标来构建一个大的时长目标模块。MMoE范式里,不同的specific task tower之间是相互隔离的,但不同的任务间往往是具备关联性的,这部分的信息提取是缺失的。我们考虑将任务间的关系视为一种概率转移关系,如此一来便自然地可以用基于贝叶斯的方法来刻画这种依赖关系。
具体地,譬如「是否>10s」目标是「是否>30s」的前置目标,那么取前者的输出作为后者的输入的一部分来建模,就描述了这样一种条件概率;譬如「是否送花」目标与「是否点赞」目标存在相关性,那么取它们分别的输出同时作为另一方的输入的一部分来建模,也即描述了概率转移。
当然有其他的级联目标模型,如esmm等,同样是用于描述目标间的依赖关系。但任务之间的关系并非都是强依赖,更多时候只是一种相关性,这时候用级联目标就过强了,而用概率转移则能兼顾到对无关系、依赖关系、相关关系的局部刻画。
先验其实还有许多,譬如同样以上述为例,当存在「是否>10s」目标与「是否>30s」目标时,前者的预估值应当不小于后者的预估值,否则则说明目标间的预测结论出现了某些不一致,那么我们便可以将这种一致性描述为一种惩罚项加入损失中,诸如此类。所谓先验,无非就是一些朴素认知的集合。
—
04
如何更好地对场景建模
最后提提对场景的建模。正如前边提到的,场景通常是需要单独拎出来考虑的维度,并且很难单纯从特征的维度去描述它。譬如对于直播场景,通常是多种UI并存的,既有基于点击的样式,也有沉浸浏览的样式,可能还有呼吸态的样式,不同UI下所外显的信息不同,这也就决定了模型所侧重的信息点不同,同时不同场景下用户的行为动机与人群结构均不同。所以对场景的建模,其实是基于不同的信息切面来建模不同场景下的异构用户群。

我们的实现方案是类似于一个网络结构的路由。譬如一份混杂样本包括点击样本(来自于点击播放UI)、播放样本(来自于沉浸浏览UI),我们按类型分流为两类样本,每一类样本分别激活其相应的网络结构。具体地,两类样本会共享一个公共模块,由此学习到用户和内容属性上的共性信息;同时有一个私有模块,期望去学习到不同场景下的系统性差异,因其异质性,所以通过私有模块来实现隔离,减少相互干扰。这里虽然列举了两个目标,但它实质上是一个单输出模型,应用时会依据样本类型,激活相应的网络结构和输出,譬如当前用户来自于点击场景时,模型激活common component + click component + click task,而其他部分保持沉默。
也许大家会有疑问,「多场景」和「多目标」的差异是什么,直接建模点击+播放目标是否更直接呢?差异在于「多」的来源,时常提到的还包括「多人群」。以答卷为例,「多目标」是在做某道题的多个选项,「多」源于行为的可选择性;「多场景」是在做不同的题,选项可能互有重叠,但题干不同,「多」源于系统模式差异;「多人群」是在做不同的卷,譬如不同地区的考生所接受的教育模式和考纲是不同的,所以他们的行为模式和知识结构会有明显分化,「多」源于用户模式差异。如此一来上述问题的答案就很清楚了,推荐有时候像是一场大型的社会实验。
—
05
Q&A
Q:模型分流时接受的一个batch都是同一种样本吗?
A:不是的,是包括多种类型的混合样本,只是我们会对不同类型的样本做分流,每类样本去激活相应的模型结构及目标。可以理解为我们拿不同类型的样本在因材施教,如果是来自于点击场景的样本,则训练模型中关于点击的模块和目标,其他类型的样本同理。
Q:能不能再详细介绍一下MemoryNet的结构?
A:它的思路是,以聚类为介质,将类簇中高信息量用户的信息传递给低信息量的用户。所以结构上,先取预指定的特征作为聚类模块的输入,然后产出聚类的描述及表征,然后当一个具体的用户进入时,根据用户的特征及聚类的描述,计算得到用户与不同聚类的相关性,并以此为权重融合相应的聚类表征,得到用户的群表征,再作为特征接回输入层,继续模型的主体部分。
Q:聚类的类别数是输入的参数还是一个可学习的参数?
A:类别数是一个超参数,相当于我们需要预先指定cluster的数目。以数量级的颗粒度去调整即可,整体上比较好调。
Q:聚类这部分是端到端学习的吗?
A:是的。聚类是一个自适应的过程,它是被学习出来的。我们之前也尝试过使用指定的方式更新聚类,但是效果不太好,所以最终还是采用了自适应的端到端学习的方式。
Q:直播场景下的推荐算法和短视频的推荐算法差异较大,能不能说一下您的体会?
A:其实这便是今天的主题,先是关于它们的共性,以及如何拿到标准化的收益;其次是它们的差异性,以及如何针对性地开展优化思路。但这些是技术层面的体会,更宽泛的体会涉及到「人」的推荐时,许多「常识」要比模型更重要。
Q:模型的embedding是共享的吗?多目标的损失函数是如何平衡的?
A:通常是,但不绝对,比如「点赞过的歌」和「点唱过的歌」,从歌曲的角度看它们似乎适合共享,但从行为的角度看则未必,因为喜欢听的歌与喜欢唱的歌其实有很大区隔。损失函数的话,可以用gradnorm一类的方法来做动态融合。
今天的分享就到这里,谢谢大家。
分享嘉宾:吴喆 腾讯音乐 高级研究员
编辑整理:吴祺尧 加州大学圣地亚哥分校
出品平台:DataFunTalk
01/分享嘉宾

吴喆|腾讯音乐娱乐集团高级研究员
本科毕业于中山大学数学系,研究生毕业于香港科技大学CSE,当前为全民K歌与QQ音乐的直播歌房推荐负责人。
02/报名看直播 免费领PPT

03/关于我们
DataFun:专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章700+,百万+阅读,14万+精准粉丝。

如若转载,请注明出处:https://www.vsaren.cn/8466.html
相关推荐
-
淘宝店铺介绍怎么写吸引人(淘宝店铺介绍字体大小)
想要店铺有所突破,那么就要从流量方面下手,流量越精准,那么转化也是越高的,店铺的情况也会越来越好。一般情况下,产品在上架初期,商家会通过一些方式来做出一定的基础销量,要注意这方面,…
-
大学兼职有哪些挣钱来的快的工作,大学兼职有哪些挣钱来的快的工作呢?
#2022开学季# 大学里,每个宿舍都会有这样几个角色:①学霸型。头脑聪明、认真好学,不上课的时候几乎都在自习室或图书馆,经常拿奖学金,深受老师喜爱。 ②兼职型。大学生活里除了上课…
-
0创业如何挣钱(如何从0创业)
我们每个人赚钱的方式是不一样的 不一样的性格的人,适合不一样的方法 今天奶爸列举五种类型的人的赚钱方法 来看看你是哪一种人吧! 第一类人是靠天吃饭 这部分人既没什么特殊技能,也没有…
-
什么叫路人粉丝,粉丝的六个级别称呼?
细数流年,不知不觉间来头条创作已逾半年,特意写下这篇文章来总结我创作过程的心路变化,既是对自己的一种反思和展望,也希望能对正在头条或正欲往头条创作的人一些启发。对阶段的划分应是多种…
-
抖音上的流量卡是真的吗_有套路吗,抖音上的流量卡是真的吗_有套路吗安全吗?
#这就是年味儿# 过年了,过年了,年味变少了,但是集卡抢红包的热情越来越高涨了。 很多人手机不离手,更多的新春活动是在手机上进行的,集卡领红包的活动各大平台上都有,红包金额还真的不…
-
拼多多无货源开店是真是假,拼多多无货源开店是真是假 不囤货 零风险?
拼多多无货源开店是真是假?不囤货、零风险解析 作为一种快速崛起的电商平台,拼多多在近年来备受关注。然而,拼多多无货源开店的议论也随之而来。有人称之为真正的零库存模式,更有人认为是骗…
-
小红书名字怎么取最容易热门,女生简短好听昵称?
(11月10日),小红书申请“老红书”商标初审被驳回的消息登上热搜。小红书回应称,注册起因是发现有第三方试图抢注多个模仿“小红书”的“老红书”商标,因此提出申请避免再被抢注。 编辑…
-
联合办公的运营模式有哪些,联合办公的运营模式有哪些优点?
据西班牙《经济学家报》网站9月10日报道,远程办公和通货膨胀正推动“共用工作空间”需求大增。 报道说,新冠疫情和通货膨胀促使企业重新思考它们的办公空间概念,并驱使它们在办公用地配置…
-
美发店互联网营销怎么做,互联网营销怎么做的?
今年找工作有多难? 1067万高校应届生,获得offer仅为46.7%,签约率仅15.4%。社会层面,据国家统计局发布的9月份就业市场数据显示,9月份全国城镇失业率为5.5%,比上…
-
怎么样可以赚钱快一点呢,怎么样可以赚钱快一点呢视频?
上一篇我们分析了当下的经济形势,以及造成目前现状的原因。经济学上讲究对症制策,知道了问题的所在,才能制定更好的有针对的措施。 不买楼房,不买车,不消费房子作为经济调控的工具(上一篇…